
 (C:)
(C:) cs300
cs300 A Survey on the Bichon Frisé
A Survey on the Bichon Frisé
DL Compilation
PyTorch began as a Python rewrite of Torch7 (Lua-based, Ronan Collobert et al.) at Facebook AI Research in 2016–17, led by Adam Paszke, Soumith Chintala, and Sam Gross. Its define-by-run eager execution made it the framework of choice for researchers, but deployment and performance demanded compilation. This post traces that arc — from eager mode through TorchScript’s limitations to the torch.compile stack announced in December 2022.
- https://www.youtube.com/watch?v=6hvJr0-adtg&t=262s
- https://www.youtube.com/watch?v=A8tO4D1Gtc0
I
1.1. PyTorch 1.x
TensorFlow (Google, November 2015) adopted a define-and-run paradigm: users built a static computation graph (SCG), then executed it in a session. PyTorch chose the opposite — dynamic computation graphs (DCG) via eager execution, where operations execute immediately as Python code runs. This meant standard Python debuggers, control flow (if/else, loops), and print statements worked out of the box, making PyTorch overwhelmingly preferred for research. The design was influenced by Chainer (Tokui et al., 2015) and HIPS/autograd (Maclaurin, Duvenaud, and Adams at Harvard). The foundational paper, “PyTorch: An Imperative Style, High-Performance Deep Learning Library” (Paszke et al., NeurIPS 2019), formalised these design decisions.
A torch.Tensor is the core data structure — a homogeneous, multi-dimensional rectangular array. Attributes [requires_grad, grad, grad_fn] drive the automatic differentiation (AD) engine: when operations are performed on tensors with requires_grad=True, PyTorch dynamically builds a DCG where torch.Tensor instances are nodes and torch.autograd.Function objects (e.g. AddBackward0, MulBackward0) are edges. Calling .backward() traverses this graph in reverse to compute gradients. Other key attributes — [size, stride, dtype, device, layout] — describe the tensor’s shape and memory layout, analogous to numpy.ndarray.
The Python API delegates computation to C++ backends for performance. ATen (“A Tensor Library”) is the core C++ tensor library, wrapping vendor-optimised libraries such as Intel MKL, NVIDIA cuDNN, and cuBLAS. ATen uses code generation (via torchgen processing native_functions.yaml) to produce boilerplate for 2,000+ operators. Alban Desmaison summarised the evolution: “i) the initial PyTorch was simply a Python wrapper + new autograd engine + TH* [the Torch7 C libraries]; ii) ATen was developed later to provide preferred C++ interfaces; iii) LibTorch is the C++ distribution of PyTorch, replacing the Python wrapper (which used Pybind11) and enabling direct C++ API access.”
TorchScript (TS) was introduced to bridge the gap between research (Python) and production (C++/mobile). It offered two APIs: torch.jit.trace records tensor operations during a forward pass with example inputs (capturing only the executed branch), while torch.jit.script parses Python source code to capture control flow. Both produce an SCG that can execute in the PyTorch JIT runtime or be exported to formats like ONNX for deployment without Python. However, TorchScript supported only a restricted subset of Python — it could not handle arbitrary data structures, many builtins, or third-party libraries — forcing researchers to rewrite code to fit its constraints, losing the “eager charm” that made PyTorch attractive in the first place.

1.2. PyTorch 2.0
torch.compile, announced in December 2022 and formally described in “PyTorch 2: Faster Machine Learning Through Dynamic Python Bytecode Transformation and Graph Compilation” (Ansel et al., ASPLOS 2024), is a domain-specific JIT compiler that converts PyTorch operations into optimised SCGs while letting arbitrary Python code continue to be interpreted. Unlike TorchScript’s “compile once, run forever” approach, torch.compile dynamically traces at runtime, achieving 93% compatibility across 163 open-source models with a single-line code change and a geometric mean speedup of 2.27× for inference and 1.41× for training on the A100.
TorchDynamo (Jason Ansel et al., Meta) is the front-end compiler responsible for Python-level graph capture. It leverages PEP 523 — the frame evaluation API added in Python 3.6 — to intercept CPython’s eval_frame function. Whenever CPython calls a function, Dynamo analyses its bytecode, identifies sequences of torch.* operations, and extracts them into FX graphs (i.e. torch.fx.GraphModule of Torch IR). Non-PyTorch code (Python builtins, I/O, third-party libraries) falls back to the default CPython interpreter. Graph breaks occur when Dynamo encounters untraceable constructs — data-dependent control flow, .item() calls, or unsupported C extensions — at which point it compiles the graph traced so far, falls back to Python, and resumes tracing after the break.
A set of guards ensures compiled graphs remain valid at subsequent calls. Guards check tensor metadata (shapes, strides, dtypes, devices), environment flags (model.training, autocast settings), and control-flow outcomes. A shape guard triggers recompilation if an input tensor’s shape changes (e.g. new batch size), causing the cached graph to be discarded and the function retraced. With dynamic=True, Dynamo generates kernels accepting variable shapes, reducing recompilation. APIs such as torch._dynamo.explain and torch.fx.graph_module.GraphModule.print_tabular help diagnose graph breaks, while fullgraph=True raises an error instead of silently falling back.

AOTAutograd (originating from the functorch project) captures both forward and backward graphs ahead of time, before execution. Normally, autograd builds the backward graph lazily during the forward pass; AOTAutograd traces both upfront so the compiler backend can optimise them jointly. It uses __torch_dispatch__, a Python-level extension point that intercepts calls at the ATen operator level — below autograd, at the C++ dispatcher — and routes them back to Python for tracing. At the end of __torch_dispatch__ tracing, AOTAutograd holds a forward graph and a joint forward-backward graph, then uses a partitioner to isolate them into separate FX graphs. It leverages PrimTorch (torch/_prims), which canonicalises PyTorch’s 2,000+ operators (including overloads) down to ~250 primitive operations — substantially lowering the barrier for backend compilers that need only implement these primitives.
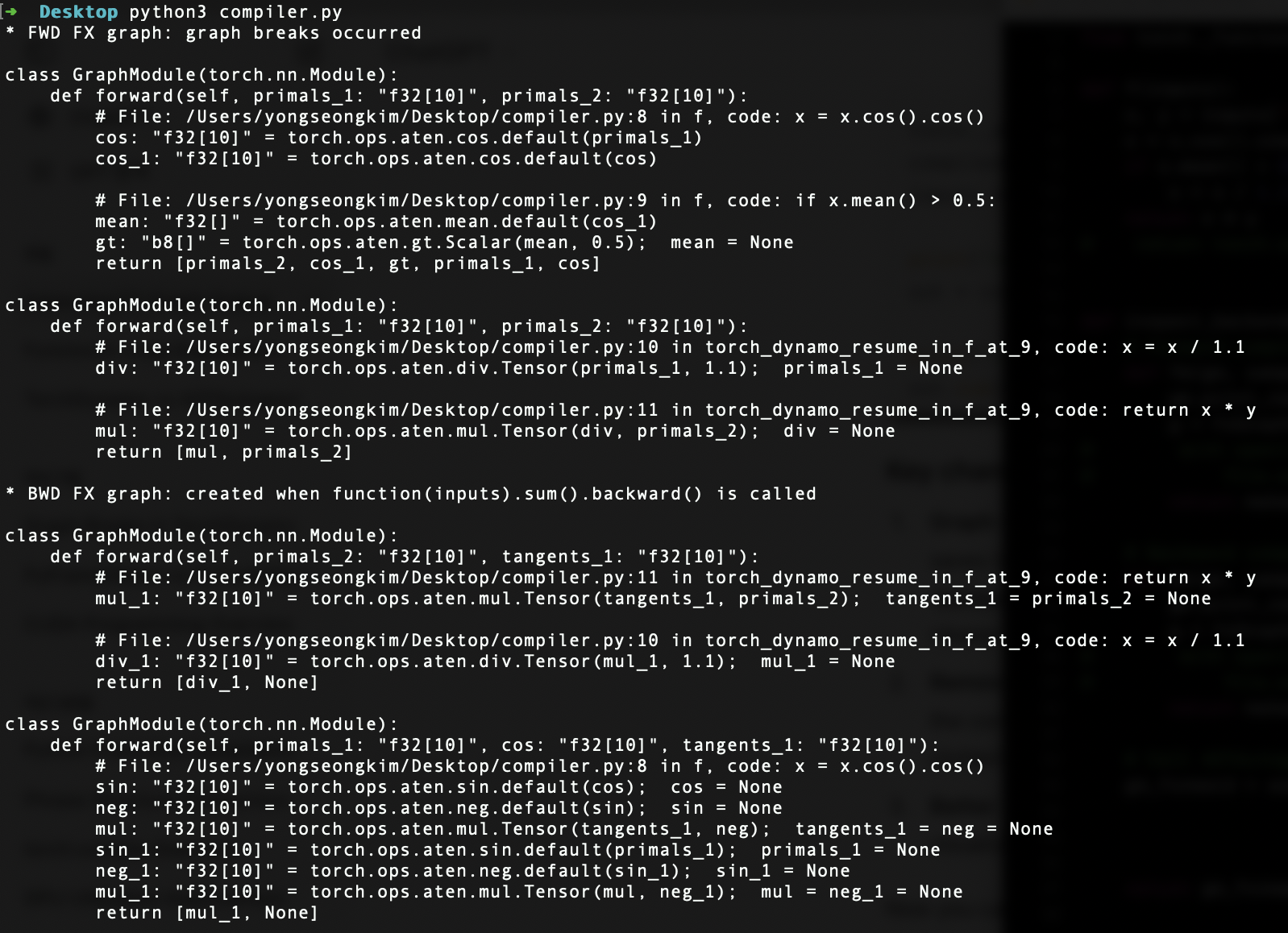
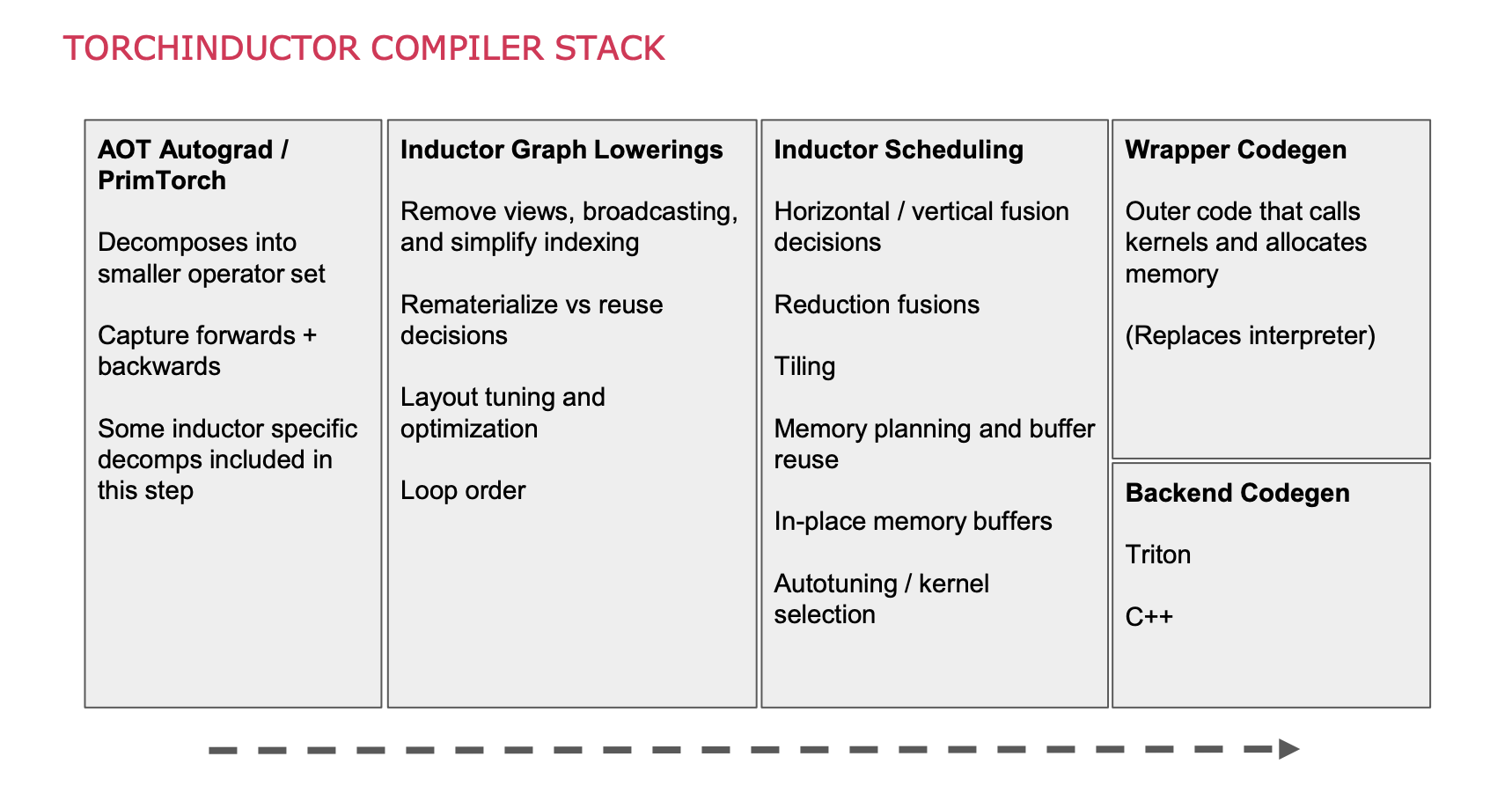
TorchInductor (Jason Ansel, Natalia Gimelshein, and team at Meta) is the default backend compiler for torch.compile. It takes ATen IR from AOTAutograd and generates optimised Triton kernels for NVIDIA/AMD GPUs or C++/OpenMP code for CPUs. Key optimisations include kernel fusion (combining multiple operations into a single kernel to reduce memory traffic), loop tiling for cache efficiency, and memory planning for allocation reuse. AOTAutograd may also apply activation checkpointing — recomputing intermediate outputs during the backward pass instead of storing them — trading computation for reduced memory; when paired with Inductor’s fusing compiler, recomputed operators can be fused for both memory and runtime savings. Alternative backends include TensorRT (NVIDIA), IPEX (Intel CPUs), XLA (Google TPUs), and custom backends registered via the register_backend API.

I gathered words solely for my own purposes without any intention to break the rigorosity of the subjects.
Well, I prefer eating corn in spiral .