
 (C:)
(C:) cs300
cs300 A Survey on the Bichon Frisé
A Survey on the Bichon Frisé
Program
A program is a sequence of instructions that directs a computer to perform a specific task. The gap between human intent and machine execution is bridged by programming languages, which vary in how much abstraction they provide over the underlying hardware. Understanding this spectrum, from assembly to Python, and the tools that translate between levels (compilers, interpreters, and their hybrids) is foundational to working effectively with any computing system.
I
1.1. Program
A program is a sequence of instructions, written in a programming language, that exists as a file on disk and becomes a process when the OS loads it into memory for execution. If one conventionally classifies programs as system programs (e.g. compilers, shells) which often provide infrastructure, and application programs (e.g. web browsers, text editors) that serve end-user needs, then the correlation between privilege level and proximity to hardware is weaker than it may appear. For instance, a shell runs with elevated privileges but never touches a device register, while a user-space game engine issues GPU commands directly through mapped memory.
In most cases, a program begins as source code, a human-readable text file (e.g. .c, .py) which expresses logic using the syntax of a given language, and must be transformed into machine code, a binary encoding of instructions specific to the target ISA, either ahead-of-time (AOT) by an available compiler or at runtime by an interpreter. This distinction induces between binaries and scripts (e.g. bash, Python), respectively. Libraries (e.g. .so, .a) bundle reusable functionality for other programs to link against, as opposed to standalone executables that run independently.
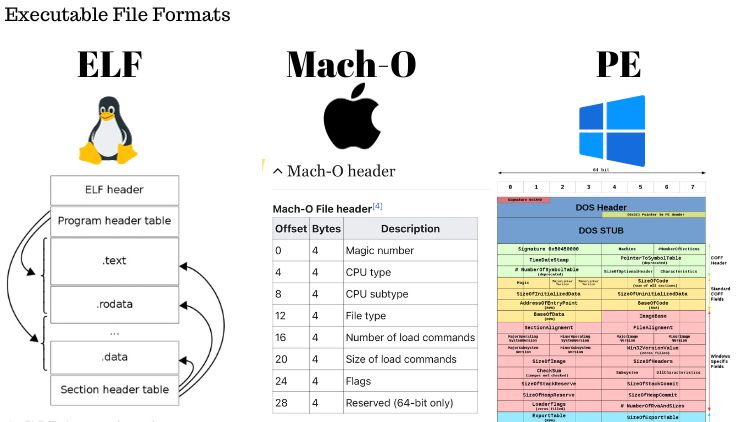
The format of a compiled program varies by OS. Linux uses executable and linkable format (ELF), Windows uses portable executable (PE), and macOS uses Mach-O. These formats encode not only machine instructions but also data sections, symbol tables, relocation entries, and metadata that the OS loader uses to map the binary into memory. Static linking embeds all dependencies directly into the executable, producing a self-contained binary, while dynamic linking defers resolution to shared libraries (e.g. .so, .dylib) at load time, reducing binary size and enabling updates without recompilation.
The application binary interface (ABI) is a set of conventions, baked into binaries at compile time, that governs how they interoperate. It specifies calling conventions, data type sizes, struct layout, and name mangling. ABI mismatches may silently corrupt data or crash at runtime, while the loader reject format mismatches outright, and thus a compiled binary targets a specific triple $(\text{OS}, \text{ABI}, \text{ISA})$. In practice, translation layers such as Apple’s Rosetta 2 can bridge ISA mismatches by converting x86_64 instructions to ARM at runtime (i.e. running Intel-compiled Adobe Photoshop on Apple Silicon becomes possible).

These distinctions compress in the ML era. For example, a PyTorch training script begins as interpreted Python but dynamically links against optimised numerical libraries (e.g. cuBLAS, cuDNN) and dispatches precompiled CUDA kernels to the GPU, crossing from script to native binary execution within a single program. Inference servers like vLLM or TGI blur the system-application line further. They are application-level software that behave like long-running system daemons, serving model predictions over network sockets while managing device memory directly.
1.2. Programming Languages
A programming language is a formal system of syntax and semantics that allows humans to express computation. Languages exist on a spectrum of abstraction. At the lowest level, assembly languages (e.g. x86, ARM, MIPS) map nearly one-to-one with machine instructions, offering direct hardware control at the cost of portability and readability. Low-level languages like C and C++ introduce structured control flow, typed variables, and manual memory management while retaining close correspondence to the hardware. High-level languages such as Python, Java, JavaScript, and Go abstract away hardware details entirely, prioritising developer productivity, safety, and portability over fine-grained control.
The execution model of a language determines how source code becomes running instructions. Compiled languages (e.g. C, C++, Rust) translate source code ahead-of-time into native machine code via a compiler, yielding fast executables but requiring a separate build step for each target architecture. Interpreted languages (e.g. Python, Ruby, JavaScript) are executed line-by-line or bytecode-by-bytecode at runtime by an interpreter, offering rapid iteration and platform independence at the cost of execution speed. JIT-compiled languages (e.g. Java via HotSpot, C# via .NET CLR, JavaScript via V8) combine both approaches: bytecode is initially interpreted, and frequently executed code paths (“hot spots”) are compiled to native code at runtime, achieving near-native performance while retaining portability.
Type systems further differentiate languages along two axes. Static typing (e.g. C, Java, Rust, Go) checks types at compile time, catching errors early and enabling compiler optimisations, while dynamic typing (e.g. Python, JavaScript, Ruby) defers type checks to runtime, offering flexibility but risking type errors in production. Orthogonally, strong typing (e.g. Python, Rust) enforces strict type boundaries with minimal implicit coercion, whereas weak typing (e.g. C, JavaScript) permits implicit conversions between types. Gradual typing systems (e.g. Python’s type hints with mypy, TypeScript) attempt to bridge this gap by allowing optional type annotations within dynamically typed codebases.
Memory management strategies reflect a fundamental trade-off between control and safety. Languages with manual memory management (e.g. C, C++) require explicit allocation and deallocation (malloc/free, new/delete), offering fine-grained control but risking memory leaks, dangling pointers, and use-after-free bugs. Garbage-collected languages (e.g. Java, Python, Go) automate reclamation through techniques such as reference counting, mark-and-sweep, or generational collection, reducing developer burden at the cost of non-deterministic pauses. Rust introduces a third approach with its ownership system and borrow checker, enforcing memory safety at compile time without runtime overhead.
Programming paradigms shape how developers structure and reason about code. Imperative programming (e.g. C) specifies explicit sequences of state-mutating instructions. Object-oriented programming (e.g. Java, C++, Python) organises code around objects that encapsulate state and behaviour, using inheritance and polymorphism for reuse. Functional programming (e.g. Haskell, Erlang, and functional features in Python, JavaScript, Rust) emphasises pure functions, immutability, and composition, reducing side effects and simplifying reasoning about concurrent code. Most modern languages are multi-paradigm, supporting combinations of these approaches, as Python and JavaScript blend imperative, object-oriented, and functional styles.
Historically, writing source code required the programmer to manually translate intent into formal syntax, a process that enforced understanding of the underlying abstractions. With AI-assisted code generation, this translation is increasingly automated, shifting the programmer’s role from authoring instructions to specifying intent and verifying correctness.
II
2.1. Compiler Framework
Low-level virtual machine (LLVM), released in 2003 by Chris Lattner, is a compiler and toolchain set designed to minimise the need for language-hardware-specific compilers. Given that a compiler pipeline generally consists of front-, middle-, and back-end, LLVM takes an intermediate representation (IR) from a front-end, apply multiple optimisation techniques, and emits an optimised IR in one of these extension: i) human-readable assembly (.ll); ii) bitcode (.bc); and iii) C++ object code (.o); LLVM follows the static single assignment (SSA) form to simplify the analysis of dependencies among variables, and so allows an efficient program optimisation-in-compilation.
In practice, a front-end compiler makes an IR with i) lexical analyser (Lexer): breaks the source code into tokens (e.g. keyword, literal, identifier); ii) parser: builds an abstract syntax tree (AST) based on the analysed tokens and the language’s grammar to represent the hierarchical structure of the source code; iii) semantic analyser: further ensures correctness of the program beyond syntax (e.g. type checking, variable declarations, and scope resolution); and iv) IR generator: transforms the examined source code into a universal IR; Modern C compilers (e.g. Clang, GCC) are self-hosting (i.e. also written in C/C++) and were developed via bootstrapping processes.
Subsequently, the LLVM Core takes a role in IR optimisations (e.g. dead code elimination), and a back-end can compile the outputted IR ahead-of-time (AOT) (i.e. llc cmd), or execute it directly using a just-in-time (JIT) compiler (i.e. lli cmd). However, as the expressive power of an IR and its ability to capture high-level semantics largely determine the sophistication of a front-end compiler, a lot of high-level languages have developed their own AST for associated infrastructures (e.g. Swift-SIL, Rust-MIR, Pytorch-TorchScript), and this led to the unnecessary coexistence of various modules (i.e. performing similar tasks) across languages and/or hardwares specific IRs.

The multi-level intermediate representation (MLIR), located in llvm-project/mlir, is a framework placed between a language’s AST and LLVM IR, enabling different levels of abstraction to coexist. While MLIR is a powerful representation, it does not intend to provide low-level machine code (e.g. .exc file) generation algorithms (e.g. register allocation, instruction scheduling), as such tasks are handled by lower-level optimisers (i.e. LLVM). Nor does it intend to serve as a source language for user-defined kernels, analogous to CUDA C++. MLIR uses dialects to represent the semantics of both general-purpose and domain-specific languages (DSLs) as first-class entities.
One has to define domain-specific operations, types, and attributes in MLIR by extending the IR to make a custom dialect. Specifically, it involves i) specifying the dialect using MLIR’s C++ API or table-driven declarative rewrite rule (DRR), ii) defining the semantics of the new operations, and iii) integrating them into the MLIR framework. Numerous custom dialects illustrate MLIR’s adaptability, including the Standard dialect for general-purpose computation (e.g. arithmetic), the LLVM dialect for LLVM IR interoperability, and the Tensor and Linalg dialects for some maths. The GPU and SPIR-V dialects are well-known domain-specific dialects for hardware acceleration.

2.2. GPU Programming
Compute unified device architecture (CUDA) is a parallel computing platform featuring compilers, libraries, and developer tools. It was created in 2006 by NVIDIA and embedded within C/C++ as a DSL for programming their own GPUs. NVIDIA CUDA Compiler (NVCC), which uses NVVM (i.e. their derivatvie of LLVM), compiles a .cu into a i) parallel thread execution (.ptx) human-readable assembly; or ii) directly executable CUDA-specific binary (.cubin); This .cu extension allows NVCC to delegate the compilation of host code (i.e. CPU-related: #include) to Clang, while focusing on device code (i.e. w/ CUDA extension: __global__, or __device__) compilation.

CUDA programming in C/C++ is generally more cumbersome due to the need for manual handling of: i) memory coalescing; ii) SMEM synchronisation and conflict management; iii) scheduling within SMs; and iv) scheduling across SMs; Thus, OpenAI introduced Triton in 2021 as Python-based framework and DSL, making it easier for ML researchers and practitioners to write optimised GPU code (i.e. primitive tensor operations). Built on top of the LLVM-MLIR infrastructure, Trition automates the first three challenges inherent to the SIM”T” model by enabling tile-based programming with multi-dimensional blocks (i.e. rather than operating on individual “T”hreads).
The Triton compiler captures the AST of a kernel, that is written in triton.language and also decorated by @triton.jit, and progressively generates IRs through MLIR dialects: i) Triton Tensor Graph IR (TTGIR): a hardware-agnostic IR for high-level opt.; ii) Triton-GPU IR: a more optimised hardware-specific IR for efficient GPU code generation; and iii) LLVM IR: LLVM lowers the IRs into an executable; While it offers finer control over SMEM and HBM compared to eager mode PyTorch (i.e. had the C/C++ backend), the throughputs of the fused softmax in Trition seems higher than both the F.softmax and JIT-compiled (i.e. TorchScript) PyTorch-native implementation.

III
3.1. Interpreter
Cross-compiling has become more accessible with LLVM, but despite extensive research, compiler development remains challenging and limits their widespread use. Accordingly, interpreters have gained popularity among ML researchers who favour iterative and also experimental workflows. Modern interpreters compile source code into bytecode, which is i) hardware-agnostic: independent of the varing ISAs; and so ii) executable on any platform (e.g. Linux, macOS, Window) with a compatible virtual machine (VM); The VM in the context often provides an abstraction layer to execute the bytecode by simulating a standardised runtime environment over an OS.
The CPython compiler’s design is outlined in PEP 339 (i.e. withdrawn), but in essence, it converts source code (i.e. .py) into bytecode (i.e. .pyc), that consists of operation codes (opcodes) and corresponding operands (i.e. if exist). Opcodes are lower-level instructions, and operands represent various entities depending on the context of opcode. Operands can vary from literal constants or immutables (e.g. number, string, tuple), variable or attribute names, or code blocks (e.g. function, class, comprehension). Similar to how assembly instructions like pop, push, and ret are represented numerically, each operand corresponds to an integer (i.e. dis.opname[int]).
CPython continues to improve its efficiency via various optimisations. Regarding opcodes, the adaptive interpreter, introduced in PEP 659, dynamically replaces generic opcodes with specialised, faster versions at runtime based on profiling data. It reduces overhead for frequently executed instructions, and so significantly enhances execution speed. One can attempt to disassemble opcodes using the dis module or examine further through the CPython source code: [Include/opcode.h, Python/opcode_targets.h, Lib/opcode.py]. In short, Bytecode, formed by combining opcodes and operands, serves as an IR which the CPython interpreter can efficiently execute.
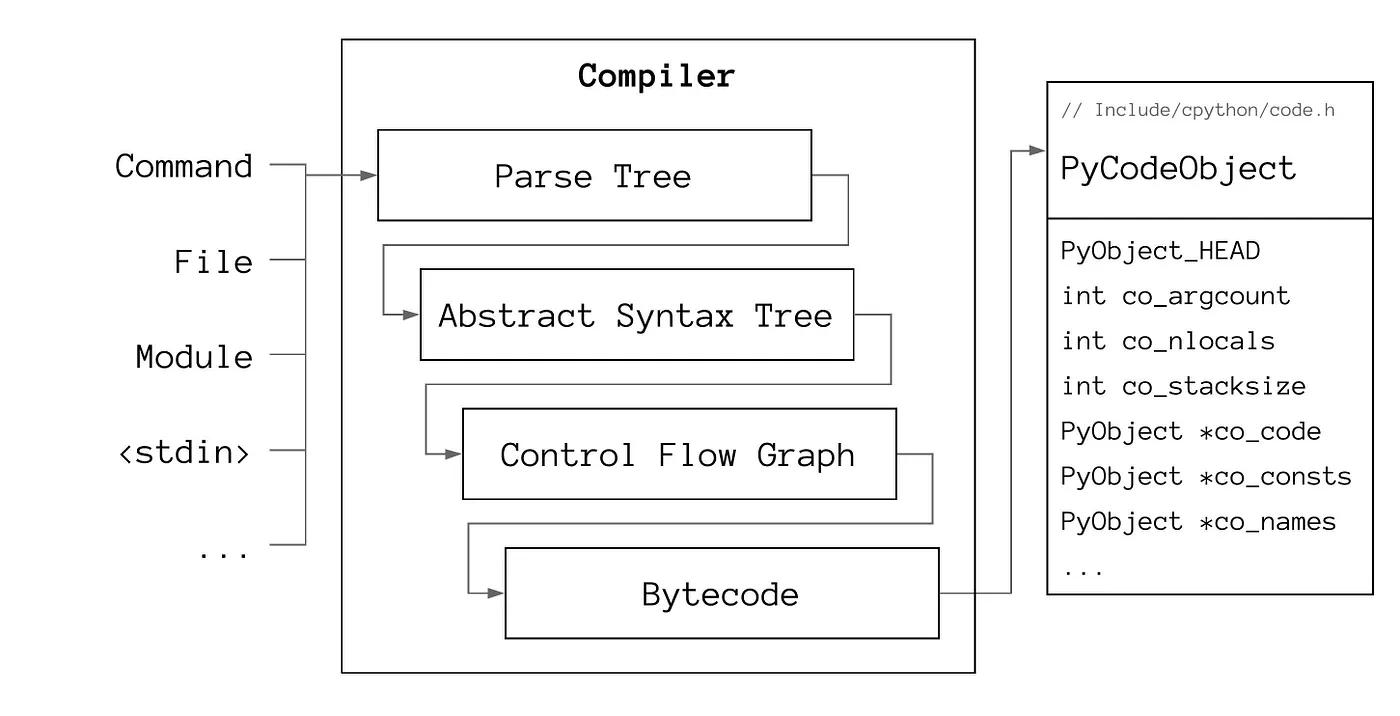
The _PyAST_Compile function in Python/compile.c is the main entry point for compilation. This generates a PyCodeObject struct that represents a chunk of executable code that has not yet been bound into a function. The struct encapsulates i) co_code: the sequence of opcodes and operands representing bytedcode instructions; ii) co_consts: constants (e.g. number, tuple) or nested PyCodeObject instances (e.g. function, class, comprehension); iii) co_names: variable and attribute names; iv) co_varnames: local variable names; v) co_freevars / co_cellvars: variables used in closures; vi) co_filename / co_name: the source file and code block name; and others;
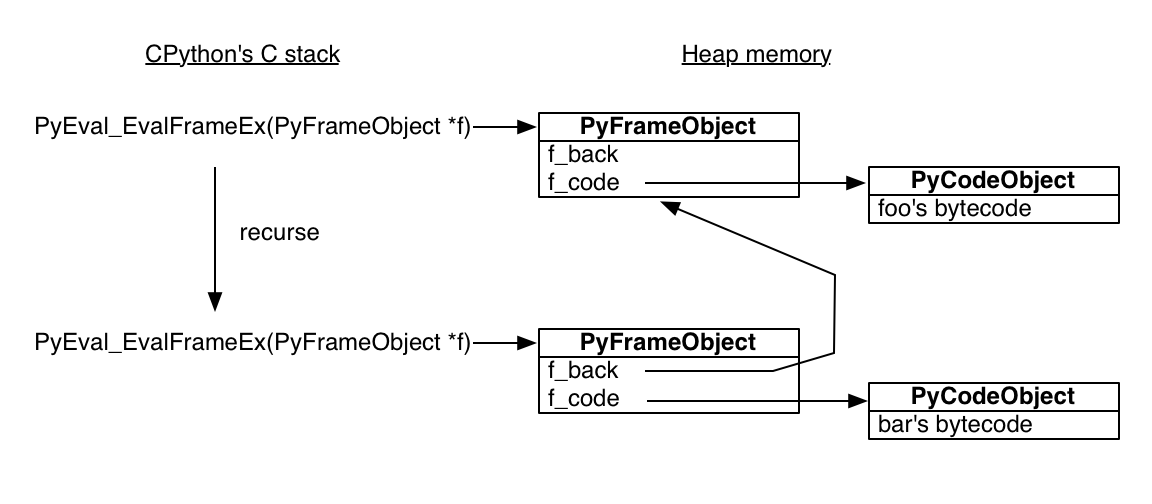
The Python virtual machine (PVM), a stack-based interpreter, then executes the compiled bytecode at runtime by simulating a CPU’s execution model (i.e. stack machine). The (legacy API-) PyFrame_New in Objects/frameobject.c emits a PyFrameObject that models a stack frame, representing the execution context of a function call. A frame object has i) f_code: a reference to the PyCodeObject; ii) f_back: a path to the last frame; iii) f_locals: local variables of the function; iv) f_globals: accessible global variables; and others; Note that f_back forms a linked list of PyFrameObject pointers, while one can examine objects and frames with the inspect or sys modules.
The _PyEval_EvalFrameDefault in Python/ceval.c serves as the main interpreter loop and, as specified in PEP 523, it is configurable. All Python objects and data structures are heap-allocated by construction. A PyCodeObject act as a blueprint, and a PyFrameObject holds the execution context for the function call, so the call stack itself is handled in the traditional stack memory. **In recent updates, Python 3.11 splits the stack frame object into: a PyFrameObject and a struct _PyInterpreterFrame. Also, Python 3.12, as proposed in PEP 709, inlines comprehensions into the code rather than compiling them as nested functions that isolate iteration variables.**
Compared to OG interpreters which traversed ASTs recursively during runtime (and suffered from slow execution), the introduction of a VM and bytecode input significantly improved performance and portability. ASTs are well-suited for representing program structure but are not optimised for efficient execution. On the other hand, a lower-level IR allows more sophisticated optimisations and custom implementations. For instance, PEP 3147 introduced the .pyc repository directory, known as __pycache__, to better organise files and improve cross-version compatibility. CPython can skip recompilation if an up-to-date .pyc file is present in the directory.
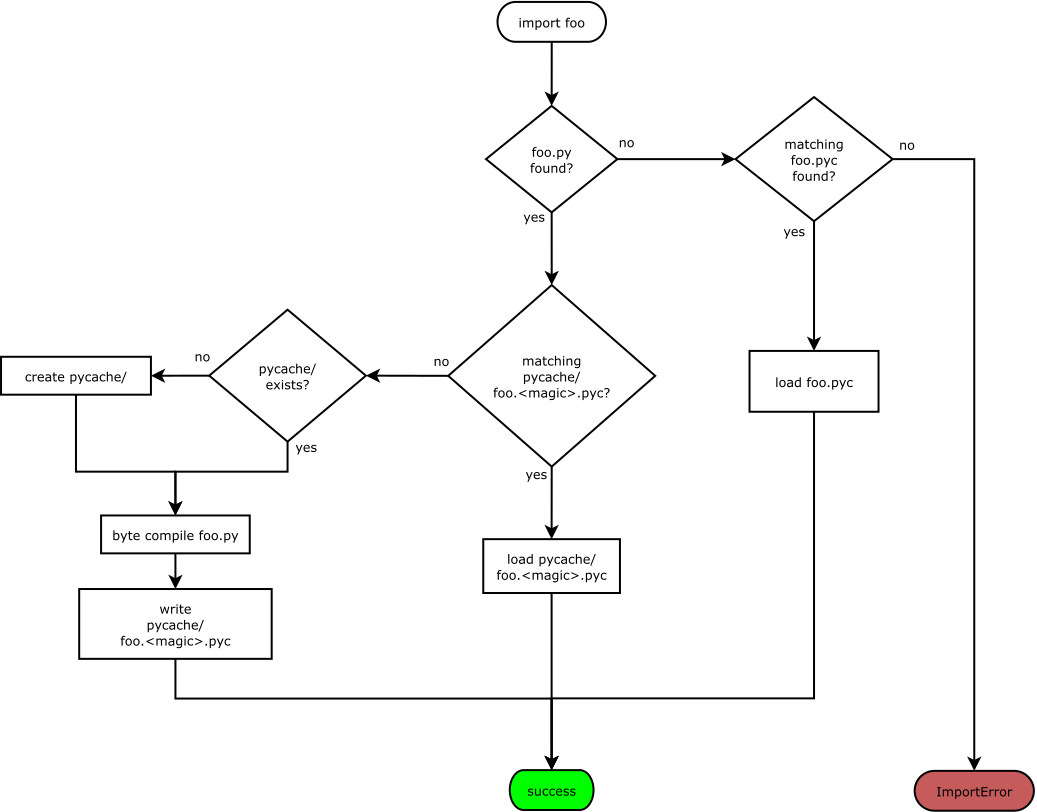
3.2. JIT Compilation
Ultimately, JIT compilers appeared to further accelerate execution speed. Given that AOS (i.e. general-case) compilation can be very slow, as Omer Iqbal mentioned in his presentation, traditional JIT compilers that can be found in other languages, such as Java (JVM) or JavaScript (V8 engine), employ multi-tiered optimisation strategies. These tiers, such as the ‘warm’ or ‘hot’ stages, adeptly detect and categorise frequently executed code paths, while the code regions will be compiled into machine code during runtime. CPython, the reference-only implementation of Python, lacks the feature, but one can find other implementations incorporating JIT compilation.

I gathered words solely for my own purposes without any intention to break the rigorosity of the subjects.
Well, I prefer eating corn in spiral .